How Site Reliability Engineering Spearheads Competitive Customer Experience
Learn how SRE principles can be applied to directly contribute to customer satisfaction
We at DNX were delighted to host another exciting webinar last week. This time with focus on how Site Reliability Engineering (SRE) can directly impact and drive a better Customer Experience (CX).
Salim Virji, a well-known Site Reliability Engineer at Google who has contributed to numerous books on reliability (e.g. the SRE Book, SRE Workbook, Implementing SLOs, and 97 Things Every SRE Should Know) kicked off the event introducing SRE. Then he dived deeper into using Site Reliability principles, such as Service Level Objectives (SLOs), to arrive at a rule of thumb to drive impactful and competitive CX.
SRE Concepts
Some important concepts to know, if you are not familiar with SRE:
Service - a product delivered over the internet.
Reliability (R in SRE) - a service or product (such as Gmail) is available and works as expected.
Site Reliability Engineering - often sits between the customer and the development group. A responsibility of SRE is to take the concepts of customer experience and bring them into the development process.
Customer experience - entails the entire a-z journey of a customer or user interacting with your service, for instance: setting up a Gmail account; sending, receiving, and searching for messages.
The responsibility of SRE is to continuously stay on top of what the customer experiences and measure that the expectations are met.
Put Yourself in the Customer’s Shoes
Rule number one: put yourself in the customers’ shoes! For example: would you, as a customer, prefer Gmail 2010 or Gmail “500” when the service degrades or fails?
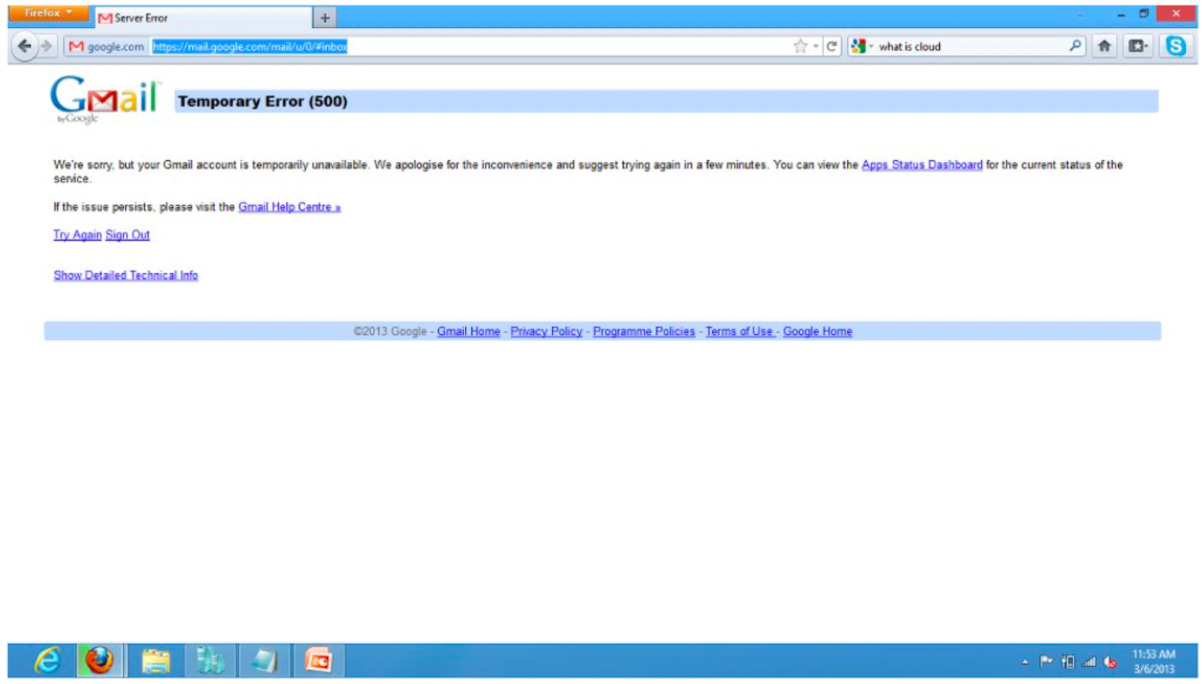
The latter (an error 500 page) is clearly not a good customer experience, nor is it the expected experience. When an issue happens, it may be better to provide a lesser user experience - slower or not as feature rich, but still allow for task completion. It is a more graceful degradation of functionality than a blank stop - a better customer experience. In summary: what the customer wants is the full and rich Gmail service, however, second to that is to get their task done. Design your fail path accordingly.
Deliver on Expected Experience
Once you have nailed down the customer experience desired, the next question is: How can reliability engineering help deliver this experience? Reliability is often taken for granted. Achieving 99% availability vs. 100% availability may seem like a small feat, but the experience difference and impact could be huge. In a service world, reliability is the most crucial feature of a system. If the system is not available, customers cannot complete their intended tasks and directly impacts satisfaction level. Reliability is key to customer experience.
Engineering ought to work on reliability at all times, not just when the system is on fire, even from the very beginning of a project. The mindset of SRE for every engineering decision also helps systems work at a larger scale. Not all projects start large, but we want the usage to grow, which means the system and service need to scale with more data and across many machines, etc. While you scale, you want to avoid scaling dependency on people. Applying SRE principles will help scale organizations sub-linearly to the size of the service, while optimizing for customer experience - by solving these challenges with software!
Thus SRE is an active part of the development team, in contrast to pure operations teams. Their development responsibilities are to create high performance (latency and efficiency) and enable easy manageability as you scale. However, organizations often place the notion of SRE purely into the operations bucket. However, if you limit SRE to only focus on onboarding services and managing on-call, it will result in limited value from your SRE investments.
SRE could contribute value throughout the entire product cycle to achieve a better customer experience outcome:
Collaborate with product owners - get involved in early design phases and contribute value before features are implemented
Evaluate existing systems to detect flawed design patterns and customer experience gaps in the product
Evaluate architecture, e.g., if too many layers are in the system to work efficiently or reduce complexity for maintainability and scale
Provide industry standard recommendations for increased reliability before product launch, such as caching, deploying load balancers, and other proven methodologies to implement these
Engage engineering and help develop software post incidents to improve reliability thinking across the organization - note, however, that SRE is and should be separate from feature development to enable good tension and good conflict; conflict is a good thing as it helps propel better products and policies forward in the pursuit of outage avoidance
This is in addition to managing incidents and the on-call process.
An Error Budget as a Rule of Thumb
With all this shared, we can arrive on the rule of thumb to bridge CX with engineering:
Service Level Indicator - a quantitative measure of an attribute of the service, such as availability, latency, etc.
Service Level Objective: an SLI at a specific target, e.g., 99.9% availability (link to most common SLO tracker)
Service Level Agreement: an SLO plus the consequence of not meeting it, e.g., 99.0% availability, makes customers drop the service
100% SLO is very rarely a true requirement. This can be the case in systems such as pacemakers, but it is more realistic to expect <100% availability - there are a number of things that can’t be controlled: network, user/system interactions, computer issues, mobile issues. That the service works 99 out of 100 times is often good enough from a customer experience.

An Error Budget provides a way to compute how much time we can spend addressing errors. Figure out how much unavailability can be handled before we know users will be unhappy with the service. From there, calculate your error budget. Example of 99.9% SLO:
1-SLO (99.9%) = 0.1%
This means: for a 1B queries / month service you have a 1M errors budget to spend
The most considerable risk for customer experience is new launches. If you have an error budget larger than zero before launch for that service, you can still launch. If, however, you have an error budget that is negative, you should not launch - it will have too much of a negative impact on already potentially unhappy users. This rule of thumb is how you can connect the CX with your reliability metrics.
Squadcast Overview
After Salim, Biju Chacko, VP Engineering at Squadcast.com, took the virtual stage and enlightened us on how modern and workflow-centric tooling can help elevate the values and outcomes for a business implementing SRE. Squadcast is an SRE-workflow and principles centric collaboration, visibility, and incident management platform.
Reliability is fundamental to customer experience. Studies show even slight latencies can cause significant drop in traffic, that means direct revenue loss in the digital world.

Incident management is often an afterthought: “We deal with it when it happens.'' When it happens, everyone jumps reactively on a video call to figure things out. The problem may get fixed, or it may be difficult to trace the root cause, so no surprise when the same incident comes back a week later. Focusing on a quick and easy standardized incident management process, and continuously becoming better at it, is low-hanging fruit for significant reliability improvement - in any size organization.
Applying SRE principles is a well-tested approach to achieve better and faster incident management. SRE principles are at the heart of Squadcast’s incident management functionality.

A straightforward process and consistent approach to dealing with problems will help simplify the path to resolution and hence resolve issues faster. There are some core elements in good SRE practice, which Squadcast has used as design principles for their workflow-centric tool:
Visibility
When criticality happens, everyone must know what to do - it is not the time for debate or chaos. Clear paths to seeking help, a sense of confidence, less panicky modes and actions, and the ability to focus helps accuracy. The ability to record what is happening and what has happened helps stakeholders quickly understand the status and how to proceed. Clear handoffs and clear paths to getting support, and easy steps to collaborate help teams avoid overload. An easy to use tool to assist every step of the process makes it easier for people to visually understand and coordinate faster - two key factors to quick resolutions.
On-call rotation
Handling incidents is very stressful and tiring. To prevent burn out, on-call rotation has to be implemented! Who is on call should be clear to everyone involved - at all times - to avoid that the same people always are being pulled in and eventually burnt out. Good tooling can keep processes clear and workloads achievable and fairly distributed.
Implement a plan
Many teams are reactive to incidents, which sets the stage for heroics. It may feel good to solve a high visibility problem, but it is bad engineering practice long term. Instead, have a plan and work that plan! SRE principles advocates using a systematic approach: use triage-examine-diagnose-treat loops.
Continuous Improvement / Continuous Reliability Engineering
After incidents happen, it is as important to implement continuous improvements into the process, such as blameless postmortems. This will continuously improve your engineering reliability culture over time and as a result improve your service reliability and customer experience.
Analytics
Prevention over reactive responses - the last pillar of a good practice is to analyze where focus and investment are needed. Organizations should strive to become data-driven to lift services to better manageability, performance, and scale.
Enable focus
Focus on what is essential and avoid toil. A big incident is like juggling knives during an earthquake. Your attention is pulled in many directions: systems, stakeholders, etc. Your attention and focus become a precious resource. Your mental energy needs to stay focused on what is critical. You must be able to manage your attention. Tooling should hence help eliminate noise, deduplicate redundant alerts, handle dependencies, etc. Automation is key to helping reduce toil. That’s where Squadcast will help.
In Conclusion
SRE guidelines help drive better customer experience
Applying SRE principles will let you arrive at a rule of thumb that will help prioritize and manage your error budget and customer satisfaction related to the service
SRE guidelines can help define a human-centric culture to help ease team overload and reduce stress, and allow small teams to do more with less (i.e., scale sub-linearly)
Squadcast can help you easily implement SRE principles and start your reliability improvement journey immediately and deliver a fast ROI
To learn more from the speakers and the discussion that followed, please view the full webinar. And if you missed our last thought-leadership webinar on the future of support, you can read all about it in our previous blog post.